Задача:
Создание метода генерации правдоподобных медицинских текстов на русском языке для обучения моделей.
Описание проекта:
Перед MIL Team стояла задача в проведение исследования методов генерации синтетических текстовых данных для медицинской области.
Основная цель заключалась в разработке метода генерации синтетических медицинских данных, определении подходов к оценке их полезности и создании набора данных медицинских анамнезов.
Решение:
Команда разработала фреймворк MedSyn — инструмент для генерации медицинских текстов, который объединяет возможности больших языковых моделей и медицинского графа знаний (MKG).
MKG использовался для отбора релевантной информации: данные о заболеваниях, симптомах и их взаимосвязях, которые применялись для создания промтов.
Для генерации текста применялись две языковые модели: GPT-4.5 для создания осмысленных медицинских заметок и LLaMA 2, адаптированная под медицинские задачи. Чтобы добиться максимальной эффективности и ускорить обучение модели был применён метод низкоранговой адаптации (LoRa), позволивший существенно сократить затраты на обучение.
Процесс генерации состоит из следующих этапов:
- Сэмплирование данных из медицинского графа: выбираются болезнь и связанные с ней симптомы.
- Создание промта: отобранные данные добавляются в промт, который подаётся на вход генеративной модели.
- Генерация анамнеза: на выходе модели формируется текст анамнеза.
- Отсеивание некачественных анамнезов: проводится проверка, и некорректные записи удаляются.
- Подготовка датасетов: создаются два набора данных — один из реальных записей, другой с добавлением синтетических.
- Обучение тестовых моделей: проводится тренировка моделей на подготовленных датасетах.
- Сравнение качества моделей: анализируется эффективность моделей, обученных на разных наборах данных.
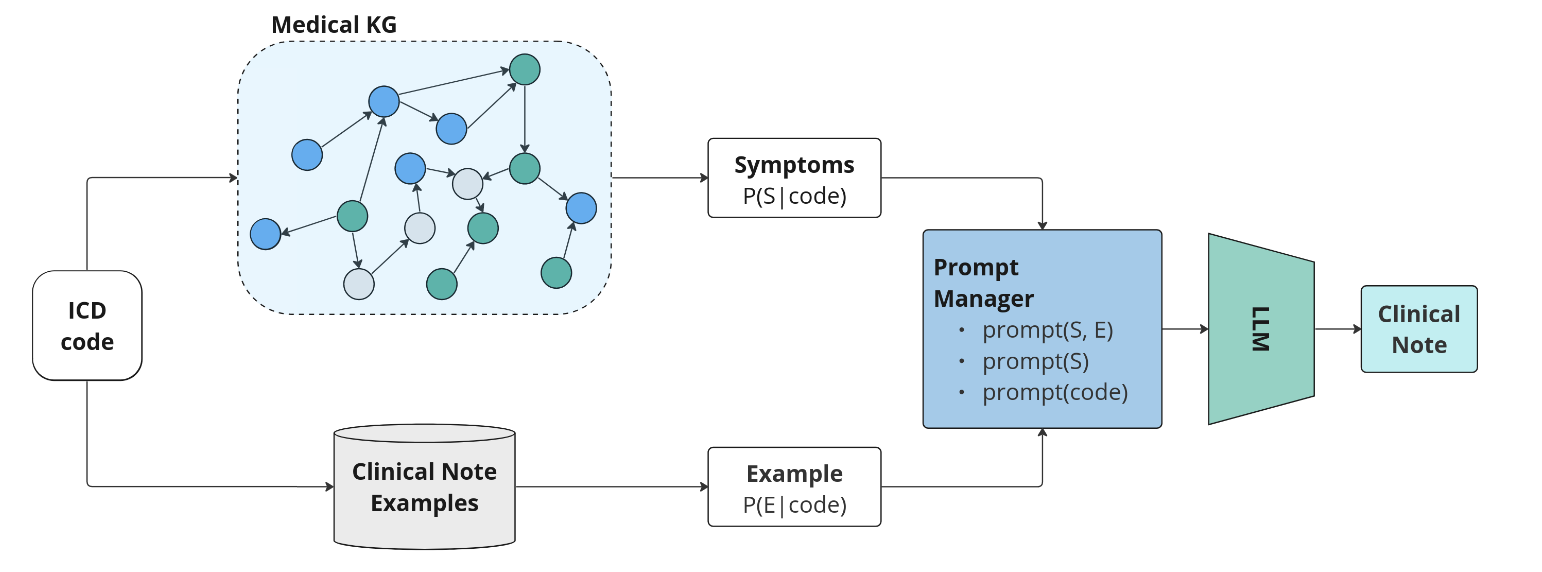
Рис. 1. Схема пайплайна генерации (этапы 1-3).
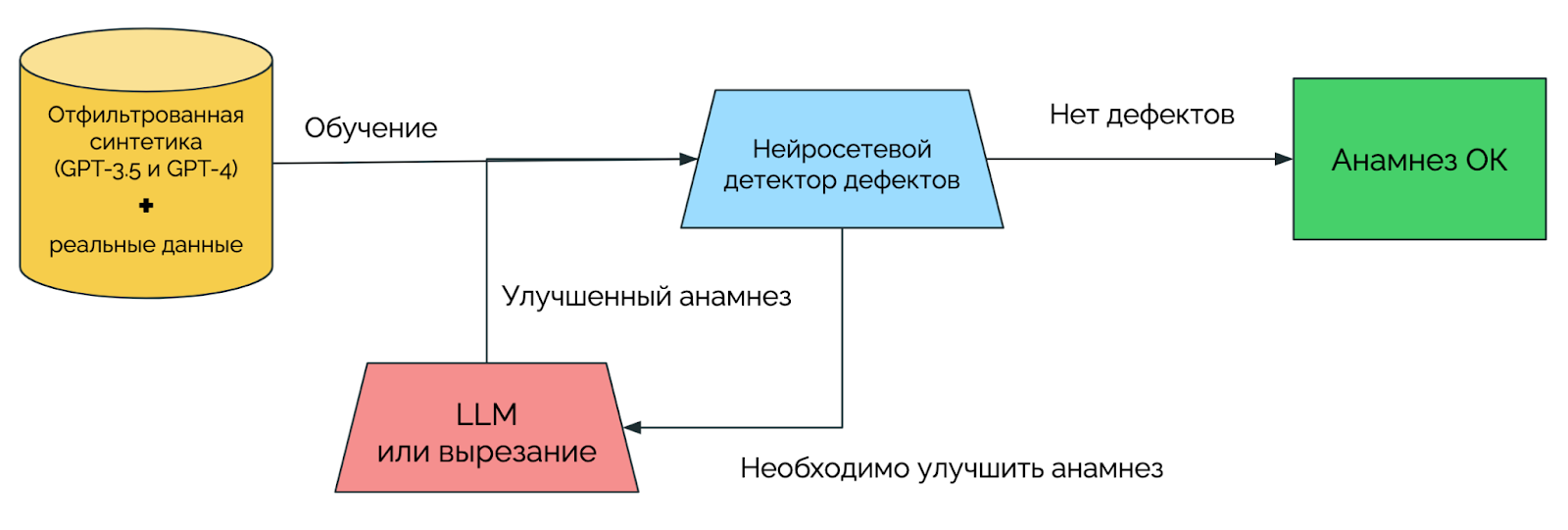
Рис 2. Схема фильтрации (этап 4).
Особое внимание уделили разнообразию сгенерированных данных. MKG обеспечивал не только их релевантность, но и широту охвата клинических сценариев, избегая повторяемости в датасете.
Тестирование синтетических данных проводилось на задачах прогнозирования кодов МКБ-10 с использованием бенчмарков RuMedTop3. Результаты показали, что включение синтетических данных повысило точность классификации на 17,8%, подтвердив их практическую ценность.
Итоги:
- Разработан фреймворк с открытым исходным кодом MedSyn для генерации синтетических медицинских данных, который позволяет создавать реалистичные клинические заметки. Для повышения точности и разнообразия генерируемых данных фреймворк использует новый метод, который объединяет специфические для заболевания и симптомы из MKG и включает примеры реальных данных в конвейер генерации LLM.
- Представлен первый и самый большой набор данных синтетических клинических текстов для русского языка, который содержит более 42 тыс. клинических текстов, охватывающих более 219 кодов МКБ-10 и более 2 тыс. симптомов.
- Проведён ряд экспериментов по генерации синтетических данных с использованием платформы MedSyn, включая сравнения между GPT-4 (OpenAI, 2023) и LLaMA с открытым исходным кодом.
- Доказано, что модель с открытым исходным кодом, при точной настройке на конкретном наборе данных, может соответствовать производительности GPT-4 или даже превосходить её.
- Опубликована научная статья: “MedSyn: LLM-based Synthetic Medical Text Generation Framework”. arXiv:2408.02056. 2024
Сгенерированные данные обеспечивают разумные улучшения при использовании для задачи классификации медицинских текстов на МКБ-коды, что приводит к повышению точности прогнозирования некоторых кодов на 17,8%. При использовании в качестве единственного источника синтетические данные также обеспечивают приемлемое качество.
Предложенный фреймворк поддерживает перенос на другие предметные области, если использовать соответствующий MKG с большим количеством данных, которые могут быть добавлены в prompt. Мы также опубликована обученную модель, обучающий набор данных (частично) и сгенерированный синтетический датасет, которые могут быть использованы для дальнейших исследований.