Описание исходной ситуации:
- большинство существующих моделей speech enchancement хорошо работает на высоких SNR;
- имеется небольшое количество общепринятых датасетов для speech enchancement;
- кроме общеизвестных метрик, таких как SDR и PESQ, важна также субъективная оценка качества звучания результирующей аудиозаписи;
- для применимости результатов моделирования в реальном времени, важно минимизировать размер окна в будущем (lookahead), который используется для предсказания текущего значения.
Цели проекта:
- Повышение качества моделей шумоподавления в случае крайне низкого значения SNR (отношение уровней сигнал/шум).
Решение MIL Team: улучшение существующих решений и создание собственных моделей, показывающих высокий прирост в терминах общепринятых метрик оценки качества аудиозаписей (PESQ, SDR) и ошибки распознавания речи (WER) для аудиозаписей с высоким уровнем шума по сравнению с речью (SNR от -10).
Для построения модели были использованы:
- открытые датасеты аудиозаписей с речью Voicebank и Librispeech;
- открытые датасеты аудиозаписей с шумами DEMAND, MUSAN.
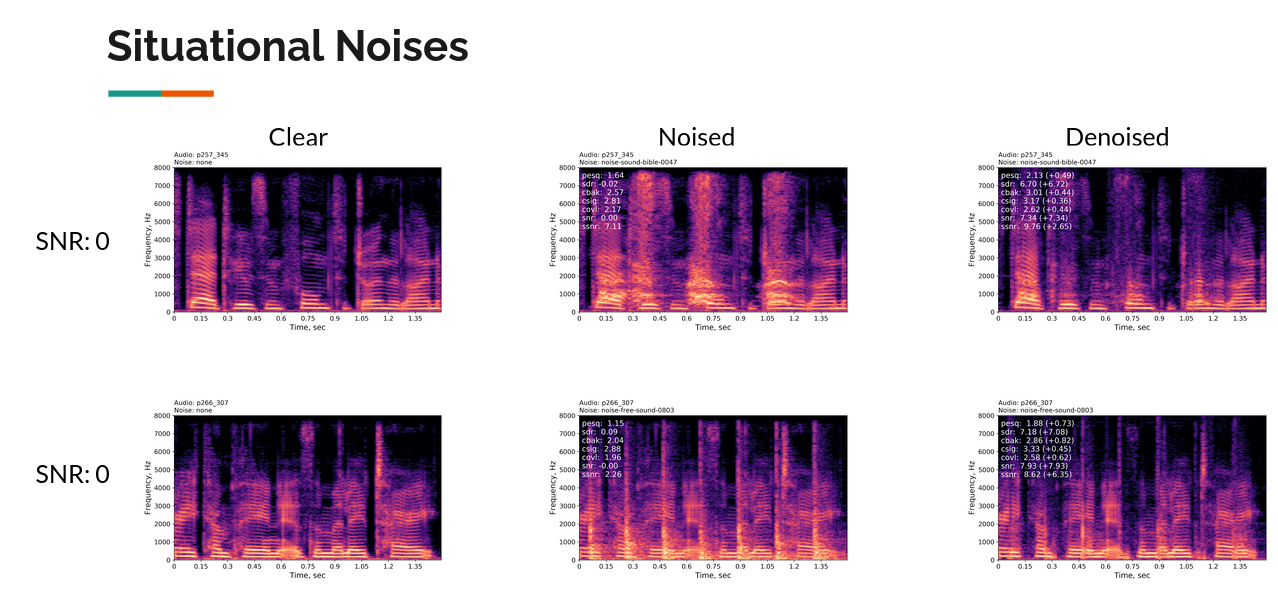
Результаты моделирования:
Obtained two promising WaveUnet models with following metrics:
8kHz: PESQ + 0.3(average), +0.3(0 SNR),
SDR +6.3(average), +9.5(0 SNR), 15.98 MMACs [Best Metrics]
8kHz + Dilations + DepthWise: PESQ + 0.3(average), +0.3(0 SNR),
SDR +6.2(average), +9.1(0 SNR), 7.49 MMACs [Smallest MAC count]
Obtained 16kHz model which is not smallest in terms of MACs, nor best in metrics, but perceptual quality is better due to higher sampling rate:
16kHz + Dilations + DepthWise: PESQ + 0.3(average), +0.3(0 SNR),
SDR +5.4(average), +8.2(0 SNR), 14.6 MMACs [Better perceptually]
Заказчик: Polyn Technology
Технологический стек: Python (PyTorch, scipy, librosa)