Описание проекта:
В условиях стремительного роста объема видеоконтента, особенно в таких областях, как стриминг и хранение данных, оптимизация технологий сжатия стала необходимой для снижения нагрузки на инфраструктуру.
Заказчик поставил перед нами исследовательскую задачу по разработке эффективных методов компрессии видеопотока на основе извлечённой семантической информации и генерации видео с использованием этой семантики. Основная цель заключалась в снижение BD-Rate видео по сравнению с кодеком h.265 при сохранении визуального качества
Решение:
Команда MIL Team начала проект с глубокого научно-исследовательского анализа существующих нейросетевых моделей сжатия видео и их ограничений. Гипотеза заключалась в том, что использование семантики и контекста видео может значительно улучшить сжатие, кодируя только наиболее важные элементы видео и снижая объем информации, которая не влияет на качество.
Были исследованы и проверены экспериментально порядка 10 методов сжатия, направленных на извлечение семантики видеоконтента, среди которых Transformers-based compression, Encoding residuals in latent space, Patch-based autoencoder, Contextual Video Model, Global semantic encoding и другие.
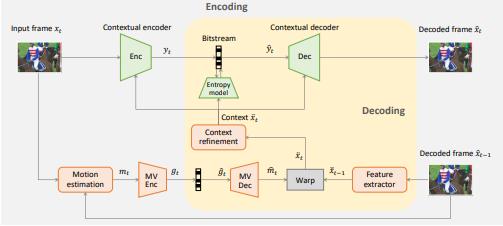
Рис.1. Пример анализируемой структуры Deep Contextual Video Model из статьи [1]
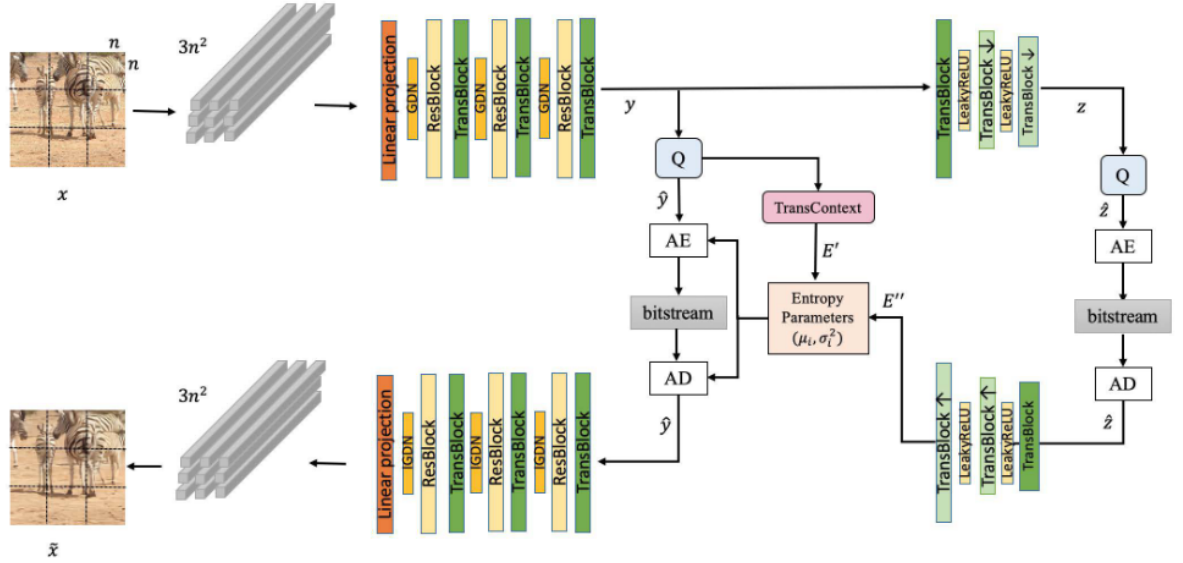
Рис.2. Пример анализируемой структуры Transformer-based variable rate модели сжатия изображения из статьи [2]
Были исследованы свойства каждого метода:
- одни лучше справляются с динамическими сценами, но хуже работают со статичными кадрами;
- другие отлично сохраняют качество при сжатии сложных кадров с множеством объектов, но могут приводить к потере деталей в простых сценах;
- некоторые методы обеспечивают высокую степень сжатия, но за счёт ухудшения визуального качества.
Именно на основе анализа этих преимуществ и недостатков командой MIL Team была предложена итоговая нейросетевая модель сжатия видео, которая объединяет два ключевых подхода:
- Семантика видео: выделение и сжатие наиболее важных объектов и областей в видеоконтенте. Модель анализирует каждый кадр с точки зрения его семантики, определяя ключевые элементы (например, лица людей, транспортные средства и т.д.), которые зритель воспринимает как важные. Эти элементы кодируются с более высокой точностью, чем фон или менее значимые объекты, что позволяет экономить на объеме данных без потери качества восприятия видео человеком.
- Контекст: используется контекстное сжатие, то есть анализирует последовательность кадров для предсказания изменений между ними. Это позволяет эффективно кодировать различия между кадрами, вместо того чтобы перекодировать каждое изображение заново. Контекстная информация помогает улучшить качество сжатия для сцен с движением или изменением объектов.
Модель нейросетевого сжатия MIL Team показала возможность быстрой адаптации к разным типам контента, что обеспечило более эффективное сжатие данных по сравнению с традиционными методами. Модель значительно снизила битрейт, сохраняя при этом высокий уровень визуального качества – это подтверждается улучшенными показателями ключевых метрик проекта: BD-Rate, PSNR, SSIM и LPIPS.
Итоги:
- Отчет о проделанной работе: MIL Team подготовила детализированный отчёт, включающий результаты всех проведённых экспериментов, глубокий анализ каждого исследуемого метода, а также рекомендации по их применению и направлениям для дальнейших исследований.
- Исходный код реализованных методов: Команда предоставила заказчику полный исходный код для всех реализованных методов видеокодирования, что позволяет заказчику использовать и модифицировать решения по мере необходимости.
- Обученные модели: Были переданы обученные модели, которые имеют высокий потенциал для дальнейшего развития и улучшений в области сжатия видео.